传输控制协议(TCP,Transmission Control Protocol)是一种面向连接的、可靠的基于字节流的传输层通信协议,由IETF的RFC793定义 。
万恶开属于TCP,后面大多数应用层为了稳定传输和传输效率,都采用了长链接。但也存在了安全隐患。也带来很多好处,让我们了解一下吧!
TCP旨在适应支持多网络应用的分层协议层次结构,互连的计算机通信网络中成对的应用程序进程之间能够依靠TCP提供可靠的通信服务来传输字节流。TCP支持双向数据流,应用程序也可以仅单向发送数据。在主机之间,TCP使用端口号标识应用程序服务并且可以多路传输数据流。
TCP是一种面向广域网的通信协议,目的是在跨越多个网络通信时,为两个通信端点之间提供一条具有下列特点的通信方式:
(1)基于流的方式;
(2)面向连接;
(3)可靠通信方式;
(4)在网络状况不佳的时候尽量降低系统由于重传带来的带宽开销;
(5)通信连接维护是面向通信的两个端点的,而不考虑中间网段和节点。
为满足TCP协议的这些特点,TCP协议做了如下的规定:
①数据分片:在发送端对用户数据进行分片,在接收端进行重组,由TCP确定分片的大小并控制分片和重组;
②到达确认:接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认;
③超时重传:发送方在发送一个分片时启动超时定时器,如果在定时器超时之后没有收到相应的确认,重发该分片;
④滑动窗口:TCP连接每一方的接收缓冲空间大小都是固定的,接收端只允许另一端发送接收端缓冲区所能接纳的数据,TCP通过滑动窗口机制提供流量控制,防止较快主机致使较慢主机的缓冲区溢出;
⑤失序处理:作为IP数据报来传输的TCP分片到达时可能会失序,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层;
⑥重复处理:作为IP数据报来传输的TCP分片可能会发生重复传输,TCP的接收端必须丢弃重复的数据;
⑦数据校验:TCP将保持它首部和数据的检验和,这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到分片的检验和有差错,TCP将丢弃这个分片,且不确认收到此报文,从而导致发端超时并重发。
客户端 服务器
| |
|-------- SYN ---------->| (1) 请求连接 (SYN=1, seq=x)
|<--- SYN + ACK ---------| (2) 确认连接 (SYN=1, ACK=1, seq=y, ack=x+1)
|-------- ACK ---------->| (3) 握手完成 (ACK=1, seq=x+1, ack=y+1)
| |
| 连接建立完成 |详细步骤:
第一次握手 (SYN)
客户端发送SYN包,SYN=1,seq=x(随机初始序列号)
客户端进入SYN_SENT状态
表示:"我想和你建立连接"
第二次握手 (SYN+ACK)
服务器收到SYN,回复SYN+ACK包
SYN=1, ACK=1, seq=y(服务器的初始序列号), ack=x+1
服务器进入SYN_RCVD状态
表示:"我收到了你的请求,同意建立连接,这是我的序列号"
第三次握手 (ACK)
客户端发送ACK包,ACK=1, seq=x+1, ack=y+1
客户端和服务器都进入ESTABLISHED状态
表示:"我收到了你的确认,连接建立完成"
核心问题:防止历史连接请求
假设场景:两次握手的问题
客户端 服务器
| |
|--- 过期的SYN(seq=100) ->| (1) 网络延迟,过期请求
|--- 新的SYN(seq=200) --->| (2) 正常的新请求
|<-- SYN+ACK(ack=101) ---| (3) 服务器响应过期请求
|<-- SYN+ACK(ack=201) ---| (4) 服务器响应新请求两次握手的问题:
无法区分新旧连接:服务器无法判断收到的SYN是否为历史请求
资源浪费:服务器会为过期请求分配资源
序列号混乱:无法确保双方序列号同步
三次握手解决方案:
第三次握手让客户端确认服务器的响应
客户端可以丢弃过期连接的响应
只有完整的三次握手才建立连接
答案:可以,但有条件
正常三次握手 + 数据传输:
客户端 服务器
| |
|-------- SYN ---------->| (1) SYN, seq=100
|<--- SYN + ACK ---------| (2) SYN+ACK, seq=200, ack=101
|-- ACK + DATA --------->| (3) ACK + 应用数据, seq=101, ack=201可以携带数据的情况:
第三次握手包可以携带数据
连接已建立,开始数据传输阶段
需要正确设置序列号和确认号
不建议在前两次握手携带数据的原因:
SYN包携带数据会增加SYN Flood攻击风险(不携带也可以攻击,效果没有带数据好,数据处理需要消耗算力和时间)
连接未完全建立时数据可能丢失
协议设计原则:握手和数据传输分离
客户端 服务器
| |
|------- FIN ----------->| (1) 客户端关闭 (FIN=1, seq=u)
|<------ ACK ------------| (2) 服务器确认 (ACK=1, ack=u+1)
| |
|<------ FIN ------------| (3) 服务器关闭 (FIN=1, seq=v)
|------- ACK ----------->| (4) 客户端确认 (ACK=1, ack=v+1)
| |
| 连接完全关闭 |详细步骤:
第一次挥手 (FIN)
客户端发送FIN包,表示不再发送数据
客户端进入FIN_WAIT_1状态
第二次挥手 (ACK)
服务器确认收到FIN包
服务器进入CLOSE_WAIT状态
客户端进入FIN_WAIT_2状态
第三次挥手 (FIN)
服务器发送FIN包,表示准备关闭连接
服务器进入LAST_ACK状态
第四次挥手 (ACK)
客户端确认服务器的FIN包
客户端进入TIME_WAIT状态
服务器收到ACK后直接关闭连接
核心原因:TCP是全双工通信
全双工连接示意:
客户端 ←→ 服务器
发送通道 ←--------- 需要单独关闭
接收通道 --------→ 需要单独关闭
双方都确认无数据丢失,传送完成才可关闭四次挥手的必要性:
双向独立关闭:每个方向的数据流需要独立关闭
数据完整性:确保所有数据传输完成再关闭
优雅关闭:给应用层时间处理剩余数据
定义和特点:
被动关闭方收到FIN后,发送ACK进入的状态
等待应用层调用close()关闭连接
如果应用层不关闭,会一直保持此状态
注意:在雷池嵌套雷池的时候:因为雷池前端长时间无数据传输,有超时主动切断TCP链接,直接切断,导致后面反向代理继续以为前站点出现502错误,造成了僵尸链接。(我是傻逼)
CLOSE_WAIT状态流程:
客户端 服务器(被动关闭)
| |
|------- FIN ----------->| 客户端FIN
|<------ ACK ------------| 服务器ACK (进入CLOSE_WAIT)
| |
| 服务器应用层处理 |
| |
|<------ FIN ------------| 服务器调用close()
|------- ACK ----------->| 客户端最终ACKCLOSE_WAIT过多的问题:
应用层BUG:忘记调用close()
资源泄露:文件描述符耗尽
连接堆积:大量僵尸连接
我们要简单了解一下TCP的头部结构和报文,为什么???我们在优化后攻击中需要对目标端口及IP地址进行伪造。知己知彼百战百胜
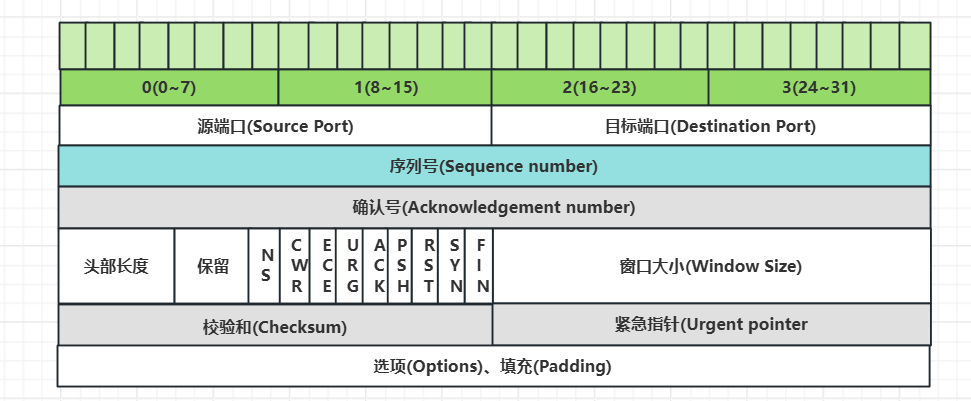
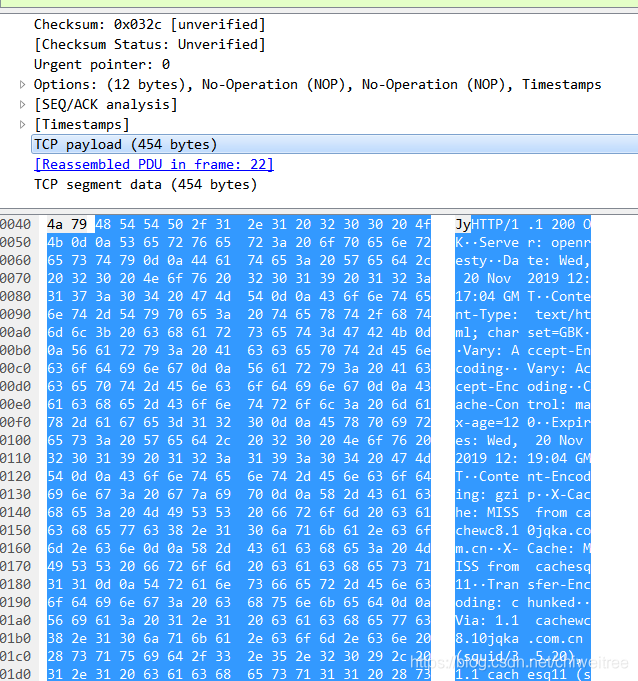
通过使用wireShark工具对访问网络的连接进行抓包我们可以得到如下信息:
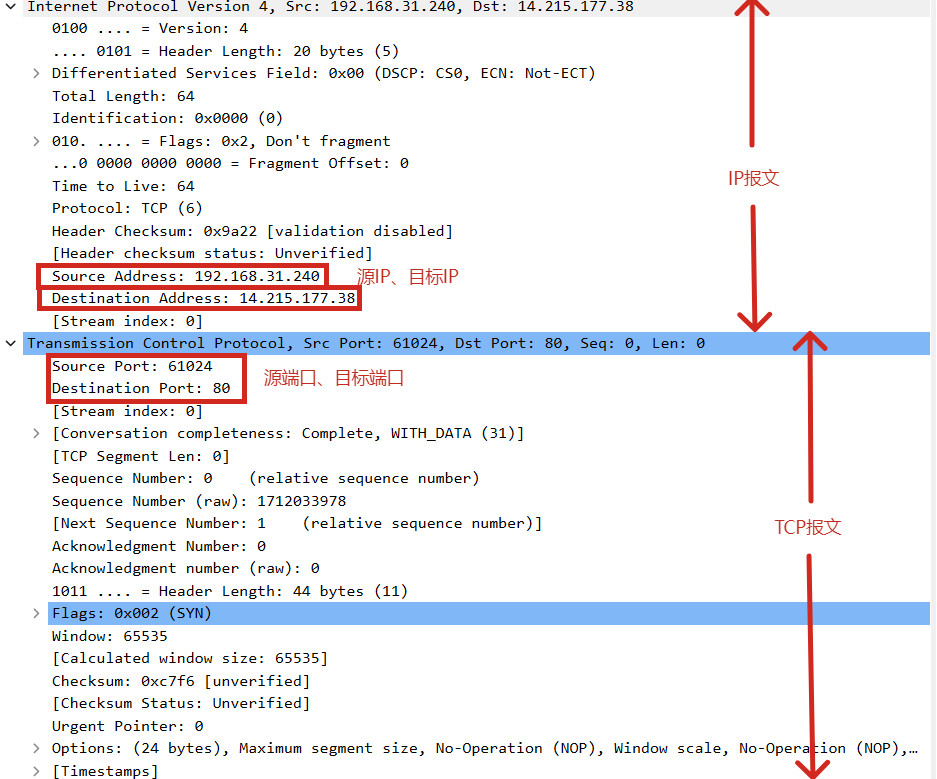
我们在优化后攻击中需要对目标端口及IP地址进行伪造,进行反射和放大一般来说,
IP层协议会存储源IP与目标IP
而TCP协议层做的事情则是存储源端口与目标端口,源IP、源端口、目标IP、目标端口唯一确定了TCP的一个四元组,一个四元组可以唯一确定一个标识,一台主机上的端口号最多有65536个,而端口号也分为好几种,有熟知端口号,端口范围为(0~1023),例如SSH连接的22端口号、HTTP连接的80端口号,已登记的端口号,端口范围为(1024~49151)等。
我们可以用NMAP扫描特定开放端口,分析手机信息。
序列号 (Sequence Number) 的规律
• 早期的操作系统(如90年代): 初始序列号(ISN)通常基于时间线性增长(例如每秒增加64000)。攻击者极其容易预测下一个连接的序列号。
• 现代操作系统: 现在的OS都采用随机算法生成ISN(遵循RFC 1948),几乎没有规律,很难通过简单的数学推算来预测精确的序列号。
基本无法复现预测序列号
序列号的作用是确定发送数据包的先后顺序,同时在建立连接、防止发送失败等场景也有重要作用,当客户端向服务端发送一个数据包时,通过数据包对应的序列号与报文长度,服务端可以唯一确定发送的是哪一段数据
同时由于网络层(IP层)并不保证发送包的顺序,通过序列号TCP协议可以解决网络包乱序、重复的问题,以保证能够按照顺序接收网络包,例如如果发送方发送包的顺序是1,2,3,4,但是到达接收方的顺序为3,2,1,4,2,那么接收方就可以通过序列号剔除多余包并按照顺序进行接收组装

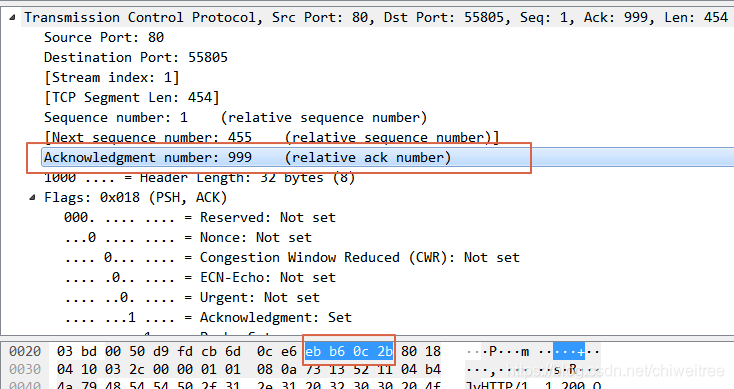
注意:序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。e.g.一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
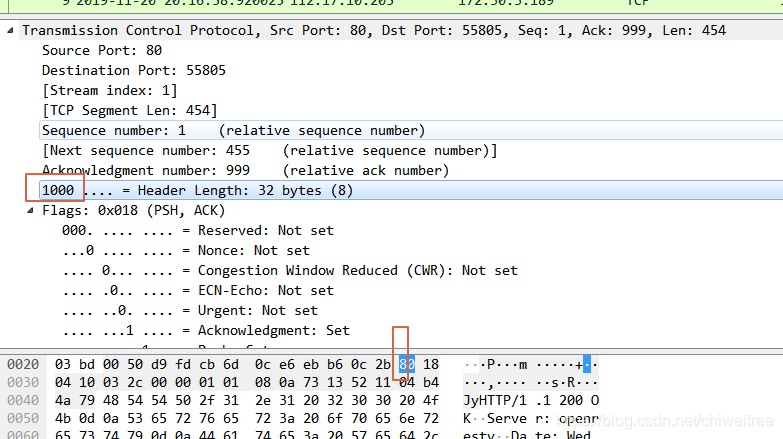
4bits。由于首部可能含有可选项内容,因此TCP报头的长度是不确定的,报头不包含任何任选字段则长度为20字节,4位首部长度字段所能表示的最大值为1111,转化为10进制为15,15*32/8 = 60,故报头最大长度为60字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
所以图上是32bytes,32个字节长度头部
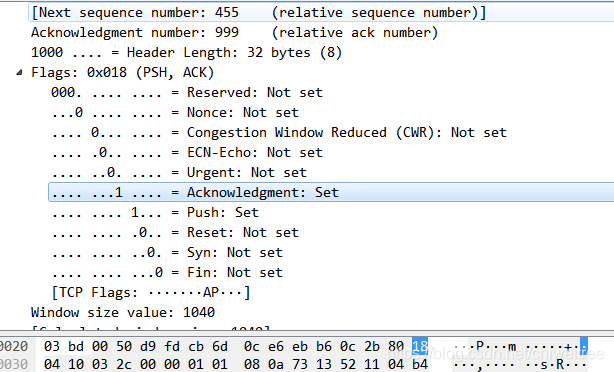
前六位都是0 保留
第七个:Urgent紧急指针标志,为1时表示紧急指针有效,为0则忽略紧急指针
下一个:ACK确认序号标志,为1时表示确认号有效,为0表示报文中不含确认信息,忽略确认号字段
下一个:push标志,为1表示是带有push标志的数据,指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队
下一个:RST重置连接标志,用于重置由于主机崩溃或其他原因而出现错误的连接。或者用于拒绝非法的报文段和拒绝连接请求
下一个:finish标志,用于释放连接,为1时表示发送方已经没有数据发送了,即关闭本方数据流
用于表示窗口大小的位数只有16位(Window Size Value),换算一下也就是65536字节(64KB),这个大小对于当下计算机系统来说肯定是远远不够用的,因此TCP协议又引入了TCP窗口缩放这个选项作为窗口缩放的比例因子,比例因子的范围为0~14,即最小0为原来大小64KB,,窗口缩放值会在三次握手时指定,例如在用wireShark抓包后,展示的窗口大小为65536
TCP攻击(通常指TCP序列号预测攻击、TCP劫持或RST复位攻击)必须落在“窗口”内,如果不在窗口内,接收方会直接把攻击包丢弃,攻击就无效了。但他是动态的浮动变化等。每次链接不一样。
窗口大小 (Window Size) 的规律
窗口本身的大小是有一定规律的,但这取决于带宽延迟积 (BDP):
• 低速/低延迟网络: 窗口较小(例如64KB)。攻击者为了命中这个小范围,需要发送海量的伪造包(暴力碰撞),很容易被检测到。
• 高速/长肥管道(Long Fat Network): 为了跑满千兆/万兆带宽,现代TCP连接的窗口通常非常大(几MB甚至几GB)。
基本上不可能了,有脚本猜测,但是也很难,除非你知道他们连击速度很慢很卡CVE-2016-5696基本被修复。
但是如果你是中间人,那你就快乐了抓包吧孩子!
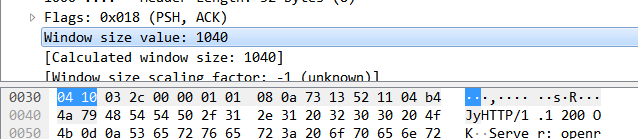
滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小是一个16bit字段,因而窗口大小最大为65535。
零窗口(ZeroWindow)
当发送方的发送速度大于接收方的处理速度,接收方的缓冲塞满后,就会告诉发送方当前窗口size=0,请停止发送,发送方此时停止发送数据
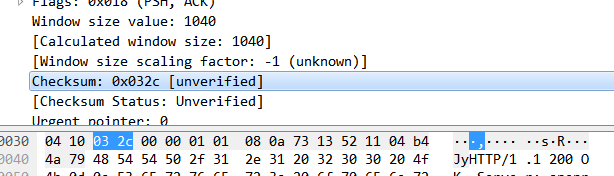
奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证
Urgent只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式
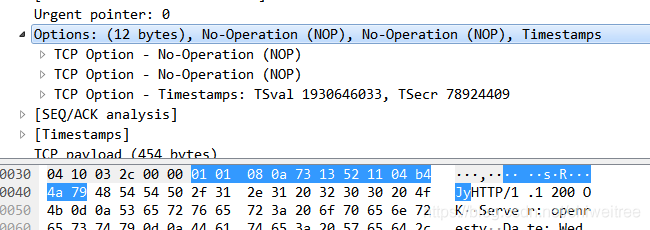
最常见的可选字段是最长报文大小,又称为MSS(Maximum Segment Size),每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN标志为1的那个段)中指明这个选项,它表示本端所能接受的最大报文段的长度。选项长度不一定是32位的整数倍,所以要加填充位,即在这个字段中加入额外的零,以保证TCP头是32的整数倍
TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段5. TCP拥塞控制详解
目标:
防止网络拥塞
公平分配网络资源
最大化网络利用率
核心机制:
发送速率 = min(拥塞窗口, 接收窗口) / RTT拥塞窗口变化:
cwnd = 1 MSS # 初始值
每收到一个ACK: cwnd += 1 # 指数增长特点:
指数增长:1 → 2 → 4 → 8 → 16 ...
快速探测可用带宽
达到慢启动阈值(ssthresh)后进入拥塞避免
# 慢启动示例
def slow_start():
cwnd = 1 # 初始拥塞窗口
ssthresh = 16 # 慢启动阈值
while cwnd < ssthresh:
print(f"发送 {cwnd} 个段")
# 假设收到 cwnd 个ACK
cwnd *= 2 # 每个RTT翻倍
print("进入拥塞避免阶段")
拥塞窗口变化:
每收到一个ACK: cwnd += 1/cwnd # 线性增长
每个RTT: cwnd += 1特点:
线性增长,谨慎探测
AIMD算法:Additive Increase, Multiplicative Decrease
触发条件:收到3个重复ACK
动作:立即重传丢失的数据包/丢包
快速重传示例:
发送方 接收方
| |
|------ Seg1 ------------>| 收到,ACK1
|------ Seg2 -----------X | 丢失
|------ Seg3 ------------>| 期望Seg2,发送ACK1
|------ Seg4 ------------>| 期望Seg2,发送ACK1
|------ Seg5 ------------>| 期望Seg2,发送ACK1
|<----- ACK1 x3 ----------| 收到3个重复ACK
|------ Seg2 ------------>| 快速重传
进入条件:检测到丢包(3个重复ACK)
动作:
1. ssthresh = cwnd / 2 # 阈值减半
2. cwnd = ssthresh + 3 # 拥塞窗口设为阈值+3
3. 每收到重复ACK: cwnd++ # 继续增长
4. 收到新ACK: cwnd = ssthresh # 恢复正常核心思想:
不依赖丢包检测拥塞
基于带宽和RTT测量
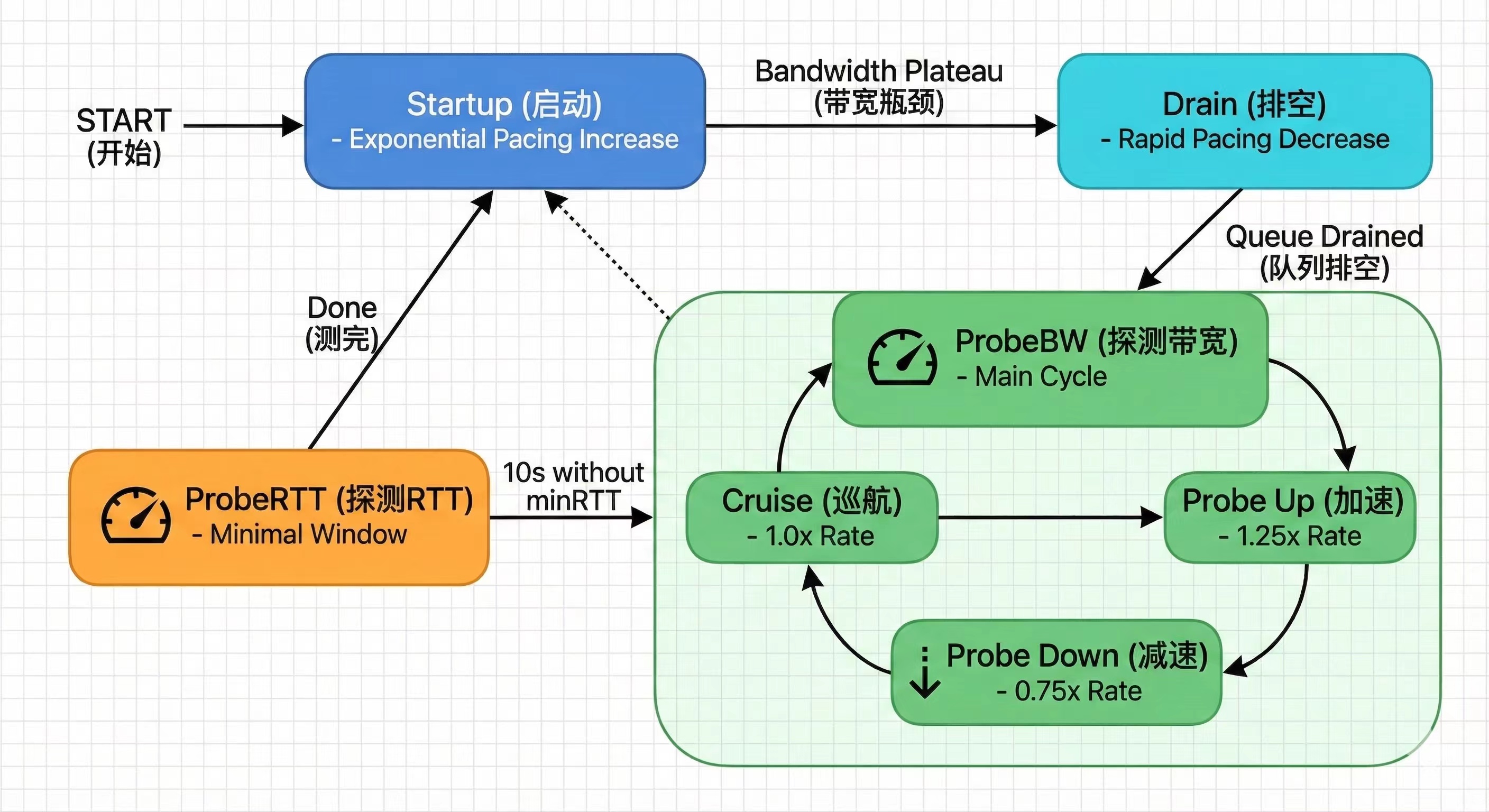
四个状态:Startup, Drain, ProbeBW, ProbeRTT
BBR算法:
发送速率 = 测量带宽 × RTT(TCP往返时间) / 数据量
Startup(起步阶段)—— 类似“地板油”(慢启动,一点点给到最大)
• 动作: 刚开始不知道路况(网络带宽),于是大脚踩油门。发送速率呈指数级增长。(如BBRplus)
• 目的: 快速填满管道,探测出网络的最大带宽(BtlBw)。
• 结束条件: 当加速了,但发现车速(吞吐量)不再提升,说明管道满了,再发就只会堵在路由器里。这时候进入下一阶段。
表现为延迟升高或丢包
2. Drain(排空阶段)—— 到达瓶颈会维持速录,而不是TCP那种直接砍半。
• 动作: 因为刚才“地板油”踩猛了,肯定有一些包堵在了路由器的缓存(Buffer)里。BBR 会迅速降低发送速率(比正常带宽低)。
• 目的: 把刚才那个阶段多塞进去的数据“排空”,让管道里的数据量回归到理想状态(即 BDP,带宽 x 延迟)。
3. ProbeBW(探测带宽)—— 避免拥堵算法
这是 BBR 绝大部分时间(98%)所处的状态。
它不再像你刚才的图那样“丢包才减速”,而是主动地“调皮”一下:
• 加速 (1.25x): 突然多发一点点。问网络:还能再快点吗?
• 如果网络回话:能!-> 更新最大带宽记录。
• 如果网络回话:不能(延迟变大了)!-> 没关系,进入下一步。
• 减速 (0.75x): 刚才试探多发了点,现在少发点,把多出来的排掉。
• 平稳 (1.0x): 保持刚才测出来的最佳速度跑一会儿。
不断尝试极限,和丢包延迟取决平衡,如果出现丢包,自动触发快速充传。
4. ProbeRTT(探测延迟)—— 避免拥堵算法
• 触发: 如果连续 10 秒钟,网络一直很忙,BBR 担心测出来的延迟(RTT)不准(因为一直在排队)。
• 动作: 强制把发送窗口降到极低(只发 4 个包),几乎是因为自己原因导致拥堵,几乎暂停发送约 200ms。
• 目的: 让路上的车都跑光,测一下在没有车流排队的情况下RTT,空跑一趟到底要多久(物理延迟 RTprop)。这保证了 BBR 的模型基准是准确的。
BBR 的聪明之处就在于,它 98% 的时间在跑高速(测带宽),只用 2% 的时间减速清场(测延迟),用这微小的牺牲换来了整体的极致性能
如图所示:
TCP性能开销:
连接建立:3次握手 (1.5 RTT)
数据传输:确认 + 重传 + 流控 + 拥塞控制
连接关闭:4次挥手 (2 RTT)
内存占用:连接状态 + 发送/接收缓冲区UDP性能优势:
无连接开销:立即发送数据
无确认开销:单向传输
无状态开销:最小内存占用
无拥塞控制:最大发送速率1. Web应用 (HTTP/HTTPS)
- 要求数据完整性
- 可以容忍延迟
2. 文件传输 (FTP, SFTP)
- 数据不能丢失
- 顺序很重要
3. 邮件传输 (SMTP, IMAP)
- 可靠性至关重要
4. 远程登录 (SSH, Telnet)
- 命令不能丢失
5. 数据库连接
- 事务完整性1. 视频直播/会议
- 实时性重要
- 丢失部分数据可接受
2. 在线游戏
- 低延迟需求
- 位置更新频繁
3. DNS查询
- 简单请求-响应
- 可以重试
4. DHCP
- 广播性质
- 简单配置
5. 音频流
- 实时传输
- 缓冲处理攻击原理:
攻击者 目标服务器
| |
|------ SYN(伪造IP) ---->| 大量SYN请求
|------ SYN(伪造IP) ---->| 服务器分配资源
|------ SYN(伪造IP) ---->| 等待ACK(永远不来)
| |
| 服务器资源耗尽 |攻击效果:
服务器半连接队列满
无法处理正常连接请求
拒绝服务攻击(DoS)
防护措施:
# SYN Flood防护
class SYNFloodProtection:
def __init__(self):
self.syn_cookies = True # 启用SYN Cookies
self.syn_backlog = 1024 # 调整半连接队列大小
self.syn_retries = 3 # 限制SYN重试次数
def handle_syn(self, syn_packet):
if self.is_syn_flood():
# 使用SYN Cookies而非分配连接状态
cookie = self.generate_syn_cookie(syn_packet)
return self.send_syn_ack_with_cookie(cookie)
else:
# 正常处理
return self.normal_syn_handling(syn_packet)# 启用SYN Cookies
# 调整半连接队列大小
# 限制SYN重试次数
#快速回收(队列满了直接拒绝)
挂CDN并开启人机验证,认证后颁发Cookise,有效防止劫持和,SYN洪水
攻击原理:
攻击者监听网络流量,伪造RST包强制断开连接
正常通信:
客户端 <--------数据流-------> 服务器
↑ ↑
| |
|------ RST (伪造) ---------> |
| |
连接被强制断开攻击条件:
知道四元组(源IP、源端口、目标IP、目标端口)
序列号在接收窗口内
网络可达
防护措施:
使用IPSec/TLS加密(有效防止VPN被劫持,推荐SSLVPN)
序列号随机化RFC 5961(缺点: 只能防盲猜,防不了中间人(因为中间人看得到你的精确序列号如途径防火墙和路由)
重点:中国的GFW怎么切断网站链接的,就用这个方法。
当你访问某个被屏蔽的网站时,防火墙检测到敏感关键词(HTTP头或SNI),它不会直接拦截你的包(那样太累)如果你一直发包会让防火墙很大的压力,而是伪装成服务器给你发个 RST,同时伪装成你给服务器发个 RST。双向掐断。
表现: 浏览器显示“连接被重置 (Connection Reset)”。
攻击流程:
1. 攻击者嗅探网络流量
2. 获取TCP连接状态信息
中间人攻击 (Man-in-the-Middle, MitM):
• 攻击者在你的网线/Wi-Fi 路径上。他能看到所有的包,所以他能精准知道当前的序列号。这是最容易成功的劫持。
4. 注入恶意数据包
5. 控制TCP会话
防护措施:
序列号强随机化
TLS/SSL加密
入侵检测系统IDS
由于现在随机序列号,和跨站防护很好,以及很难遇到劫持攻击。
这是 DDoS 攻击中的霸主。因为它不需要建立 TCP 连接(无握手),且利用 UDP 的“无状态”特性,攻击者可以伪造受害者的 IP 去请求公网上的服务器。
• 原理:
1. 攻击者伪造受害者的 IP (1.2.3.4)。
2. 向公网上开放的 DNS、NTP、SSDP、Memcached 服务器发送一个小请求(比如问“你是谁?”)。
3. 这些服务器会向 1.2.3.4 回复一个巨大的包(比如几千倍大小的回复)。
常用协议:
• DNS 放大: 请求根域名服务器,返回大量记录。
• NTP 放大 (Monlist): 请求时间服务器列表。
• Memcached 放大: 这是最恐怖的,放大倍数可达 5万倍。
• LDAP / CLDAP 放大: 利用企业的目录服务端口。
现状: 非常好用,成本极低,流量极大。通过 UDP 直接把受害者的带宽塞满。
攻击原理:
# Slowloris攻击模拟
class SlowlorisAttack:
def __init__(self, target_host, target_port):
self.target = (target_host, target_port)
self.sockets = []
def start_attack(self):
# 建立大量TCP连接
for i in range(1000):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(self.target)
# 发送不完整的HTTP请求
sock.send(b"GET / HTTP/1.1\r\n")
sock.send(b"Host: target.com\r\n")
# 故意不发送\r\n\r\n结束标志
self.sockets.append(sock)
# 定期发送额外的头部,保持连接
while True:
for sock in self.sockets:
try:
sock.send(b"X-Custom-Header: value\r\n")
time.sleep(10)
except:
# 连接断开,重新建立
self.sockets.remove(sock)
self.establish_new_connection()2. 技术原理
这个最恶心TMD。HTTP 协议规定,一个完整的请求头(Headers)必须以两个连续的换行符 (\r\n\r\n) 结尾,代表“头发送完毕,服务器你可以开始处理了”。
Slowloris 的攻击逻辑:
1. 建立连接: 完成 TCP 三次握手。
2. 发送部分头部: 发送 GET / HTTP/1.1。
3. 无限续命: 只要连接快超时了,就发送一个无意义的头,比如 X-Ignore: 1,然后继续保持沉默。
4. 死不结尾: 永远不发送 那个关键的 \r\n\r\n。
这样,Web 服务器(特别是 Apache 1.x/2.x 这种基于线程的)会认为客户端网速慢,还在努力发数据,所以会一直保留这个连接线程,直到达到服务器的最大并发连接数上限。
3.解决方法
调整 Nginx 超时配置
原理: 既然攻击者想拖时间,我就规定超时丢弃。
在 Nginx 配置文件 (nginx.conf) 的 http 或 server 块中添加:
http {
# 1. 限制请求头接收时间 (防 Slowloris)
# 默认可能是 60s,改成 5s。
# 正常人谁发个 HTTP 头要 5 秒?肯定是攻击。
client_header_timeout 5s;
# 2. 限制请求体接收时间 (防 Slow POST)
# 如果两个连续的数据包之间间隔超过 10s,就断开。
client_body_timeout 10s;
# 3. 限制连接总时长 (可选)
# 无论你多慢,这个连接最多只能活 60秒。
keepalive_timeout 60s;
}
攻击原理:
1. 发送POST请求头,声明大量数据
2. 极其缓慢地发送POST数据
3. 占用服务器连接资源
4. 导致正常用户无法访问2. 技术原理
和上面一个逼样!
服务器(特别是传统的 Apache,或者未优化的 Nginx)处理连接的线程数/进程数是有限的(比如默认 1024 个)。
1. 发送 Header: 攻击者发送一个 POST 请求,关键在于 Header 里带上 Content-Length: 10000000(声明有一个很大的数据包要传)。
2. 正文慢传: 服务器收到 Header 后,打开大门准备接收 Body。攻击者以极慢的速度(例如每分钟 1 个字节)发送数据。
3. 维持连接: 每次发送 1 个字节,都能重置服务器的“空闲超时计时器”,让服务器觉得连接还是活的。
解决方法:
限制缓冲区大小
原理: 既然攻击者利用大 Content-Length 来骗资源,我就限制最大允许上传的大小。(尤其是图床Willem被揍过)
1. Nginx 层面: 调小 client_header_timeout 和 client_body_timeout,对慢速连接零容忍。
2. 架构层面: 只要套上 Cloudflare(开启小黄云),慢速攻击对你就是无效的。(套CDN)
http {
# 限制上传文件大小。博客传图片一般 10MB 够了。
# 攻击者如果声称要传 1GB,直接拒绝。
client_max_body_size 10m;
# 限制请求头缓冲区
large_client_header_buffers 4 8k;
}
这是近几年被学术界和黑产挖掘出来的,利用防火墙(Middlebox)的特性来做 DDoS。
• 原理:
• 世界上有很多防火墙(比如某些国家的审查防火墙、企业防火墙),当你发送某种违规请求时,它们会试图拦截并给你发一个“拦截页面”或 RST 包。
• 攻击者伪造受害者的 IP,向这些防火墙发送触发拦截的包。
• 防火墙向受害者发送大量的拦截响应数据。
利用构造IP层/TCP层/http头或处罚注入语句造成反射。
优势: 这是 TCP 协议的反射,比 UDP 更难防,因为看起来像是合法的 TCP 回包。
难以防御
• 看起来像正常流量: 受害者收到的是正规的 HTTP 响应或者是标准的 TCP 包。
• 利用基础设施: 攻击者不需要控制僵尸网络,只需要利用公网上的防火墙设备。这些设备带宽极大,性能极强。
• 没有握手: 受害者会莫名其妙收到大量带数据的 PSH+ACK 包,但本地根本没有这个连接记录,导致系统资源消耗
攻击场景:
真实客户端 IP: 192.168.1.100
攻击者伪造源IP发送TCP包
伪造的TCP包:
源IP: 192.168.1.100 (伪造)
目标IP: 192.168.1.1
源端口: 随机
目标端口: 80# IP欺骗防护
class AntiSpoofing:
def __init__(self):
self.trusted_networks = ['192.168.1.0/24']
def validate_source_ip(self, packet):
source_ip = packet.src_ip
# 1. 检查源IP是否在合理范围
if self.is_bogon_ip(source_ip):
return False
# 2. 反向路径验证
if not self.reverse_path_forwarding_check(source_ip):
return False
# 3. 地理位置验证
if not self.geo_location_check(source_ip):
return False
return True时代不一样了,随着技术的更新,会话劫持,RST拒绝攻击随着Linux内核升级,以及SSl普及变得难度跟高,除非在路径中间者获取完整数据包才可以。
SYN洪水,在个别局域网可以尝试,大部分的路由器有防止SYN和Vlan划分。(还是可以操作的)
Slowloris & Slow POST 还算可以这个是真恶心。但是可以很轻缓解。套了CDN基本上就不可能了。
TCP作为互联网的核心协议,其设计体现了网络通信的复杂性和可靠性要求:
三次握手和四次挥手确保连接的可靠建立和优雅关闭
复杂的状态管理(如TIME_WAIT、CLOSE_WAIT)保证网络的稳定性
精心设计的头部结构支持各种高级功能
拥塞控制机制保证网络的公平性和效率
与UDP的差异体现了可靠性与性能的权衡
安全隐患和防护需要多层次的安全策略
理解TCP的这些机制对于网络编程、系统优化和安全防护都至关重要。在实际应用中,需要根据具体场景选择合适的协议和优化策
